Private LLMs are cheaper than you think
7 min readVlad Koval
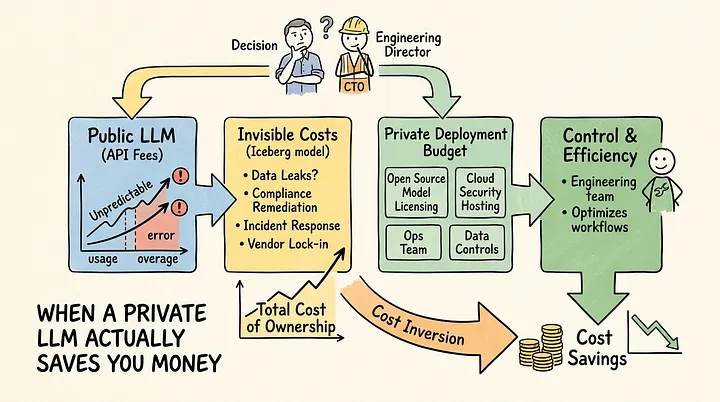
Most engineering teams I talk to treat public LLM APIs as the cheap option and private deployment as the expensive one. That framing is understandable. When you sign up for an API key, the bill starts at zero. When you stand up a private LLM, the bill starts at “how many GPUs do we need and for how long.” The upfront asymmetry feels decisive. But total cost of ownership rarely works the way the upfront numbers suggest, and I keep coming back to this one when I look at what mid-market companies are actually spending.
The assumption that public APIs are cheaper breaks down somewhere around the 6-to-18-month mark, depending on usage volume and your compliance posture. Below that threshold, public APIs probably win on pure cost. Above it, the math starts inverting in ways that aren’t obvious from a pricing page.
What the API invoice doesn’t show you
Token costs are visible. Everything else tends to hide in other budget lines.The first hidden cost is API overage and usage volatility. Public LLM pricing is per-token, which sounds predictable until your usage scales. A team that starts with a few internal tools quickly discovers that token consumption grows non-linearly: longer context windows, more chained calls, retrieval-augmented pipelines that make multiple model calls per user query. Engineering teams building on top of GPT-4-class models have reported month-over-month cost jumps of 40–80% during product growth phases, with no corresponding change in their pricing agreement. You can set hard limits, but hard limits break user experience. You can optimize prompts aggressively, but that takes engineering time that also costs money.
The second hidden cost is what I’d call compliance drag. If your company handles anything regulated (healthcare, finance, legal, HR data), using a public API means your data leaves your perimeter. That creates a compliance surface you have to manage continuously. Legal review of the vendor’s data processing agreement. DPA negotiations. Periodic audits to confirm the vendor’s certifications are current. Incident response planning for the scenario where the vendor has a breach. None of this shows up on the API invoice, but it’s real labor, often from expensive people.
The third is incident response exposure. When a public model vendor changes behavior (and they do, without warning), your downstream systems break in subtle ways. When a vendor has an outage, you have no lever to pull. When a model update causes your fine-tuned behavior to drift, you’re debugging a black box. Each of these events costs engineering hours. Multiply that across a year and it’s a meaningful number.What private deployment actually costs
Private deployment has a real cost structure, and I want to be honest about it rather than wave it away.
You need compute. For a capable open-source model (Llama 3, Mistral, Qwen, or similar), you’re typically looking at one to four A100-class GPUs for inference, depending on model size and throughput requirements. On a major cloud provider, that’s roughly $10,000-$30,000 per month for dedicated GPU instances, or less if you use spot/reserved pricing. You can also run smaller quantized models on less expensive hardware if your latency tolerance allows it.You need someone to operate it. Deployment, monitoring, updates, and the occasional model swap when a better open-source release comes out. This is probably 0.25–0.5 of a senior engineer’s time on an ongoing basis, plus a meaningful upfront investment to get the stack running.
You need infrastructure around it: a serving layer, logging, rate limiting, a way to swap models without downtime. If you’re building on something like vLLM or Ollama with a decent orchestration layer, this is weeks of work, not months.
So the realistic private deployment budget for a mid-market company might be $15,000-$40,000 per month in compute plus $150,000-$250,000 annualized in engineering labor (blended, including the upfront build). Call it $350,000-$700,000 per year fully loaded.That sounds like a lot. But consider what you’re getting: predictable cost regardless of usage volume, no per-token overage, no compliance surface on the data path, and full control over model behavior.
When the math actually inverts
The crossover point depends on your token volume and your compliance overhead. Here’s a rough way to think about it.If you’re spending $30,000 per month on public API calls today, and that number is growing 20% quarter-over-quarter, you’ll be at $50,000-$60,000 per month within a year. Over a two-year horizon, that’s $1M+ in API spend alone, before compliance labor and incident costs. A private deployment in that same window might cost $700,000-$900,000 fully loaded, with a flatter cost curve as usage grows.
The compliance picture shifts the math further. A single HIPAA or GDPR incident involving a public AI vendor can cost more than a year of private deployment infrastructure. That’s not a hypothetical. Companies have paid seven-figure settlements for data handling failures that were significantly less dramatic than “we sent patient records through a third-party AI API.”
### A pattern I keep seeing
The companies that feel this most acutely are the ones that started with a narrow internal use case (a support bot, a document summarizer) and then found that use case sprawling into production systems touching regulated data. The original API integration was fine. The sprawl is what creates the exposure. By the time the compliance team gets involved, the cost of remediation often exceeds what a private deployment would have cost from the start.What open-source models make possible now
Three years ago, the capability gap between public APIs and open-source models made this conversation mostly theoretical. GPT-4 was so much better than the available open-source alternatives that cost was almost a secondary concern.
That gap has narrowed significantly. Llama 3.1 70B and Mistral Large 2 are competitive with GPT-4 on most enterprise tasks that don’t require cutting-edge reasoning. For document processing, classification, summarization, and structured extraction (which is most of what mid-market companies actually need), the quality difference is hard to justify paying a 5–10x cost premium for.This is the part of the equation that changes the math most for companies evaluating the switch now versus two years ago. The private large language model option has gotten meaningfully better without getting meaningfully more expensive.
Aimprosoft’s team wrote about the broader strategic considerations behind this shift in their piece on private LLM enterprise strategy, including how to think about model selection and deployment architecture for different compliance contexts.
Where private deployment still doesn’t make sense
I don’t want to oversell this. There are real cases where public APIs remain the right choice.If your token volume is low and stable, the economics don’t invert. If you have no regulated data in your AI workflows and no realistic path to having any, the compliance argument disappears. If you don’t have the engineering capacity to operate infrastructure (and can’t hire it), the operational burden of private deployment can easily exceed the cost savings.
The honest version of the recommendation is: if you’re spending more than $20,000 per month on public API calls, or if any of your AI workflows touch regulated data, the total cost of ownership calculation is worth doing seriously. Not because private deployment is always cheaper, but because the assumption that it isn’t is often wrong in ways that become expensive to discover later.
The companies that do this analysis carefully tend to find that the decision window for switching is narrower than they expected, and that the right time to start planning is before the compliance team forces the conversation.
More in artificial-intelligence




Venture
Write for entrepreneurs, founders, and builders.
Share startup lessons, growth tactics, and founder stories with readers on the same journey.
One free account across In Plain English, Stackademic, Venture, and Cubed.
How it works- Startups & entrepreneurship
- Marketing & growth
- Productivity & leadership
- Founder stories & lessons learned
Sign in
Google or GitHub
Complete profile
Takes a few minutes
Get approved & publish
Start sharing
Why write for Venture?
Entrepreneurship is rarely a straight path. The lessons worth sharing are learned while building.

Comments
Loading comments…