The Open Source RAG Stack: A Complete Guide to Building Retrieval-Augmented Generation Systems
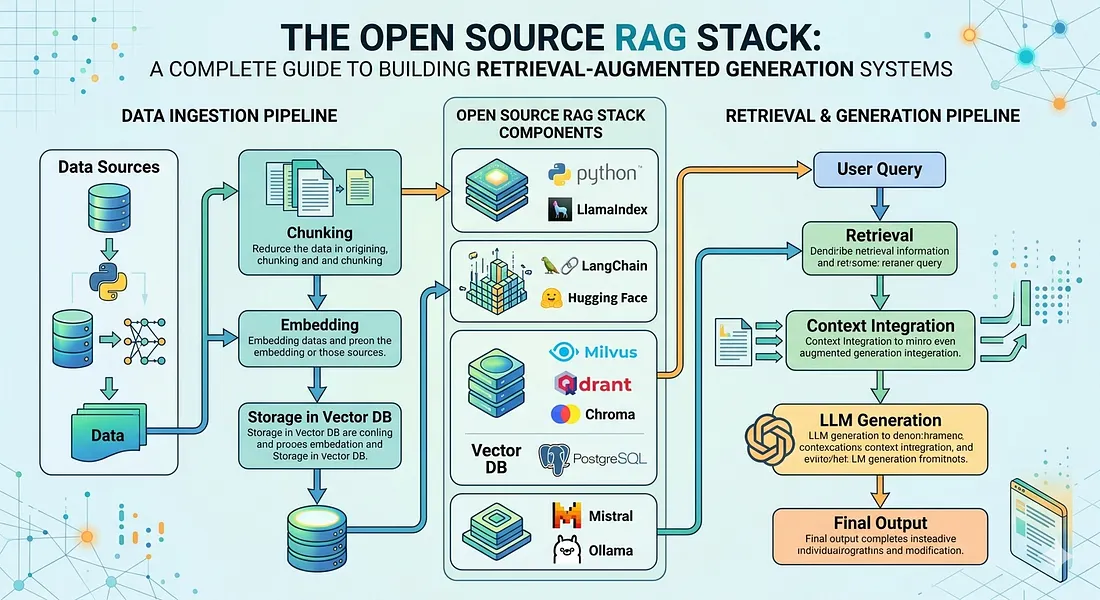
Retrieval-Augmented Generation (RAG) is revolutionizing how AI systems deliver accurate, context-rich responses by combining large language models (LLMs) with real-time information retrieval. For developers and enterprises seeking flexibility, transparency, and scalability, open-source RAG stacks offer a powerful alternative to proprietary solutions.
This guide breaks down the seven essential layers of the open-source RAG architecture, highlighting the best tools for each stage — from data ingestion to frontend deployment.
🧱 Layer-by-Layer Breakdown of the Open Source RAG Stack
1. 🖥️ Frontend Frameworks
Build intuitive user interfaces for interacting with your RAG system. Popular Tools:
- NextJS — React-based, ideal for production-grade apps
- SvelteKit — Lightweight and fast
- Streamlit — Great for data apps and prototypes
- VueJS — Flexible and developer-friendly
2. 📦 Vector Databases
Store and retrieve embeddings efficiently for semantic search. Top Choices:
- Weaviate — Schema-aware and scalable
- Milvus — High-performance for large-scale deployments
- pgVector — PostgreSQL extension for vector search
- Chroma — Lightweight and developer-friendly
- Pinecone — Managed vector DB with fast indexing
3. 🔍 Retrieval & Ranking
Find and rank relevant documents based on query embeddings. Recommended Tools:
- FAISS — Facebook’s fast similarity search
- Haystack — Modular NLP pipeline
- Weaviate — Built-in retrieval and ranking
- Elasticsearch — Powerful full-text search
- Jina AI — Neural search and multimodal support
4. 🧠 LLM Frameworks
Orchestrate prompts, memory, and tool use across agents. Leading Libraries:
- LangChain — Agentic workflows and tool integration
- Haystack — End-to-end RAG pipelines
- LlamaIndex — Document indexing and retrieval
- Huggingface — Model hosting and transformers
- Semantic Kernel — Microsoft’s agentic AI SDK
5. 🧬 Language Models (LLMs)
Generate responses based on retrieved context. Open-Source Models:
- LLaMA — Meta’s foundational model
- Mistral — Lightweight and fast
- Gemma — Google’s open model
- Phi-2 — Microsoft’s compact model
- DeepSeek — Chinese open-source LLM
- Qwen — Alibaba’s multilingual model
6. 🧠 Embedding Models
Convert text into vector representations for semantic search. Popular Options:
- HuggingFace — Wide selection of embedding models
- LLMWare — Enterprise-grade embeddings
- Nomic — Open-source vector tools
- Sentence Transformers — High-quality sentence embeddings
- JinaAI — Multimodal embeddings
- Cognita — Specialized for domain-specific tasks
7. 🔄 Ingest & Data Processing
Prepare and pipeline data for indexing and retrieval. Best Tools:
- OpenSearch — Scalable search engine
- Haystack — Document parsing and indexing
- LangChain — Ingestion chains and loaders
- Apache NiFi — Flow-based data automation
- Apache Airflow — Workflow orchestration
- Kubeflow — ML pipeline automation
🚀 Why Choose an Open Source RAG Stack?
- Customizable: Tailor each layer to your domain and data
- Transparent: Full control over data flow and model behavior
- Scalable: Deploy across cloud, edge, or hybrid environments
- Cost-Efficient: Avoid vendor lock-in and reduce licensing fees
- Community-Driven: Benefit from rapid innovation and shared knowledge
What is RAG and why is it important? RAG combines LLMs with external data retrieval to produce accurate, context-aware responses — ideal for enterprise search, chatbots, and knowledge assistants.
Can I mix and match tools across layers? Yes. The stack is modular — choose tools based on performance, compatibility, and your team’s expertise.
How do I choose the right vector database? Consider scale, latency, schema support, and hosting preferences. For example, pgVector is great for PostgreSQL users; Milvus suits large-scale deployments.
Are these tools production-ready? Most are battle-tested in real-world applications. Combine with proper monitoring, testing, and governance for enterprise use.
How do I deploy a full RAG system? Start with ingestion and embeddings, set up retrieval and ranking, connect to an LLM via LangChain or Haystack, and expose via a frontend like Streamlit or NextJS.
POSTS ACROSS THE NETWORK
Best Medical Alert Systems for Seniors in 2026
The Open Source RAG Stack: A Complete Guide to Building Retrieval-Augmented Generation Systems
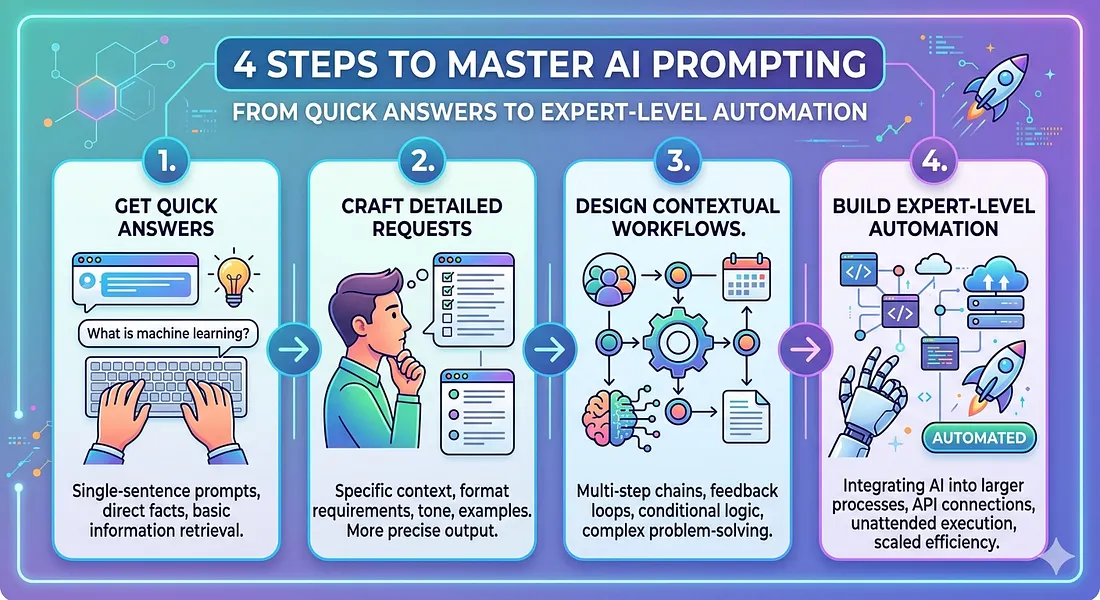
4 Steps to Master AI Prompting: From Quick Answers to Expert-Level Automation

Prompt Injection Is the SQL Injection of AI — And Most Systems Are Unprotected
